1 简介
Elasticsearch由于其功能强大,开箱即用等特点在企业中用的越来越广泛。但是在使用过程中经常会遇到很多问题,对于对ES不是很熟悉的人来说,有些问题甚至有些奇怪。比如通过rest api查询集群状态为green,但是kibana连接es却提示超时;还有集群在添加节点后或,在通过api查询一些状态的时候却长时间没有返回结果。
就ES应用本身来讲,问题的排查思路可以从两个大方向开展:
- 数据层面:index, shard
- 程序层面:线程池,如search,write等;task,如pending task;hot thread,看看es主要的CPU消耗等
即如果集群状态是green仅说明shard的主副本没有丢失,并不代表集群当前数据的写入和查询也是正常的。
2 排查思路
通常来讲先从大方向如集群健康状态等全局的层面进行排查,如果没有问题,在进行层序层面的排查,如线程池,task等,同时也可以借助必要的jvm工具如jstack,jmap已经集群外的监控工具进行排查。
对于简介中提到的第一种情况,经排查发现是从es中查询数据的脚本效率非常低,而es是部署在kubernetes中的,可能是由于jvm的默认机制,es进程只使用2个CPU。在排查过程中,发现search线程被卡住了,队列中有100多个search任务卡住了。
通过GET /_cat/thread_pool,GET /_cluster/pending_tasks,发现是search任务卡住了,这是因为只能使用2个CPU。在通过GET _tasks?actions=*search&detailed接口查看任务的详细信息,最后通过POST _tasks/_cancel?actions=*search取消队列中的查询任务。
对于简介中提到的第二种情况,由于当前集群中某个节点故障,shard出现了unsingd的情况,在节点加入后,shard会进行恢复迁移。但是并没有注意cluster.routing.allocation.node_concurrent_recoveries的配置,通过下面的命令检查,此值为200,非常大。
curl -X PUT "localhost:9200/_cluster/settings"
cluster.routing.allocation.node_concurrent_recoveries的值如果比较大的话,一般会出现如下的现象:
集群 unassigned 分片,一开始下降的速度很快。大约几分钟后,数量维持在一个固定值不变了,然后,然后就没有然后了,集群所有节点 generic 线程池卡死,虽然已存在的索引读写没问题,但是新建索引以及所有涉及 generic 线程池的操作全部卡住。
通过下面的命令修改上述配置
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 5,
"indices.recovery.max_bytes_per_sec": "40mb"
}
}'
上面的值要根据具体情况进行设置,设置太小,则unsigned的分片恢复需要较长的时间,设置太大,则可能线程池卡死。
3 补充知识
3.1 基本概念
3.1.1 ES线程池(thread pool)
ES中每个节点有多种线程池,各有用途。重要的有:
- generic:通用线程池,后台的node discovery,上述的分片恢复(node recovery)等等一些通用后台的操作都会用到该线程池。该线程池线程数量默认为配置的处理器数量(processors) * 4,最小128,最大512.
- index:index/delete等索引操作会用到该线程池,包括自动创建索引等。默认线程数量为配置的处理器数量,默认队列大小:200.
- search:查询请求处理线程池。默认线程数量:int((# of available_processors) / 2) + 1,默认队列大小:1000
- get:get请求处理线程池。默认线程数量为配置的处理器数量,默认队列大小:1000.
- write:单个文档的index/delete/update以及bulk请求处理线程。默认线程数量为配置的处理器数量,默认队列大小:200,在写多的日志场景,一般会将队列调大。还有其它线程池,例如备份回档(snapshot)、analyze、refresh 等,这里就不一一介绍了。详细可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
3.1.2 集群恢复之分片恢复
ES 集群状态分为三种,green、yellow、red。
- green 状态表示所有分片包括主副本均正常被分配;
- yellow 状态表示所有主分片已分配,但是有部分副本分片未分配;
- red 表示有部分主分片未分配。
一般当集群中某个节点因故障失联或者重启之后,如果集群索引有副本的场景,集群将进入分片恢复阶段(recovery)。此时一般是 master 节点发起更新集群元数据任务,分片的分配策略由 master 决定,具体分配策略可以参考腾讯云+社区的这篇文章了解细节:https://cloud.tencent.com/developer/article/1334743 。各节点收到集群元数据更新请求,检查分片状态并触发分片恢复流程,根据分片数据所在的位置,有多种恢复的方式,主要有以下几种:
- EXISTING_STORE : 数据在节点本地存在,从本地节点恢复
- PEER :本地数据不可用或不存在,从远端节点(源分片,一般是主分片)恢复
- SNAPSHOT : 数据从备份仓库恢复
- LOCAL_SHARDS : 分片合并(shrink)场景,从本地别的分片恢复
PEER 场景分片恢复并发数主要由如下参数控制:
- cluster.routing.allocation.node_concurrent_incoming_recoveries:节点上最大接受的分片恢复并发数。一般指分片从其它节点恢复至本节点
- cluster.routing.allocation.node_concurrent_outgoing_recoveries :节点上最大发送的分片恢复并发数。一般指分片从本节点恢复至其它节点
- cluster.routing.allocation.node_concurrent_recoveries :该参数同时设置上述接受发送分片恢复并发数为相同的值。 详细参数可参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html
集群卡住的主要原因就是从远端节点恢复(PEER Recovery)的并发数过多,导致 generic 线程池被用完。涉及目标节点(target)和源节点(source)的恢复交互流程,后面分析问题时我们再来详细讨论。
3.2 问题复现与剖析
为了便于描述,我用 ES 6.4.3版本重新搭建了一个三节点的集群。单节点 1 core,2GB memory。新建了300个 index, 单个 index 5个分片一个副本,共 3000 个 shard。每个 index 插入大约100条数据。 先设定分片恢复并发数,为了夸张一点,我直接调整到200,如下所示:
curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{
"persistent": {
"cluster.routing.allocation.node_concurrent_recoveries": 200 // 设定分片恢复并发数
}
}'
接下来停掉某节点,模拟机器挂掉场景。几分钟后,观察集群分片恢复数量,卡在固定数值不再变化:
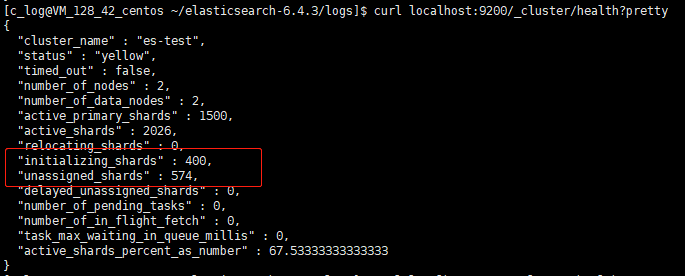
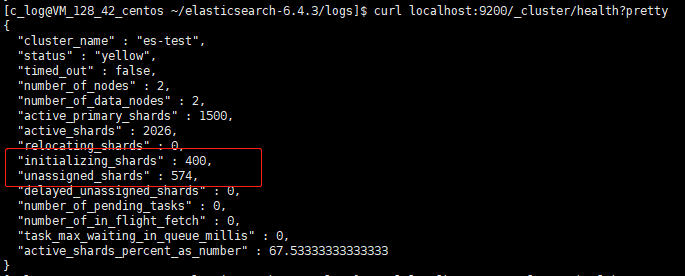
通过 allocation explain 查看分片分配状态,未分配的原因是受到最大恢复并发数的限制:
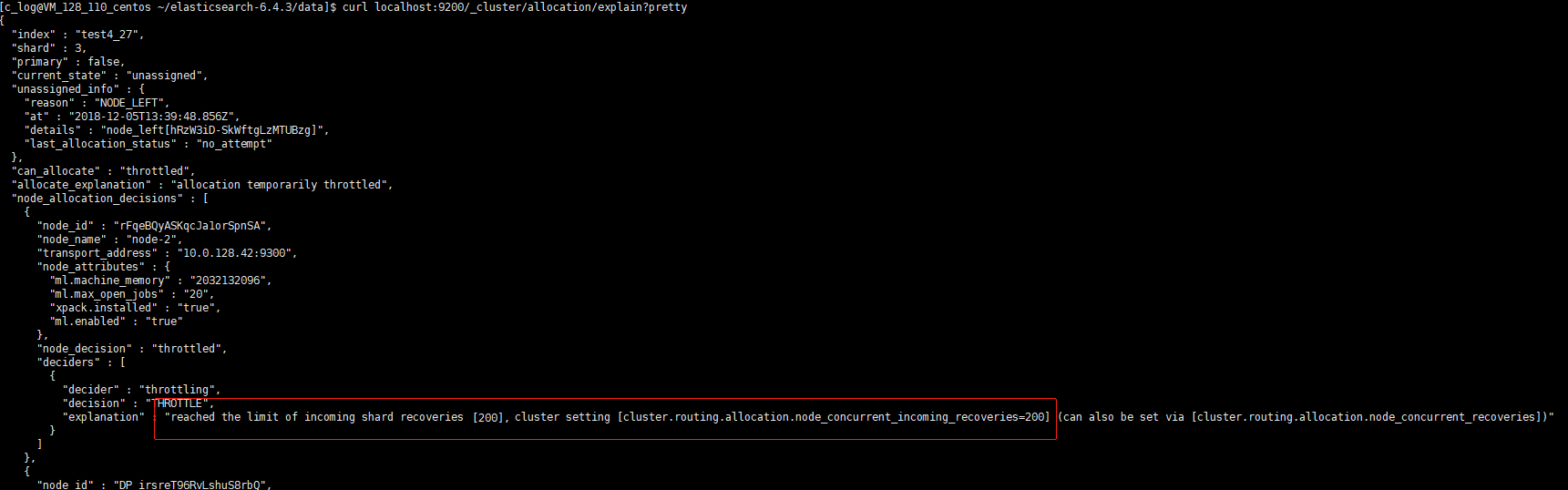
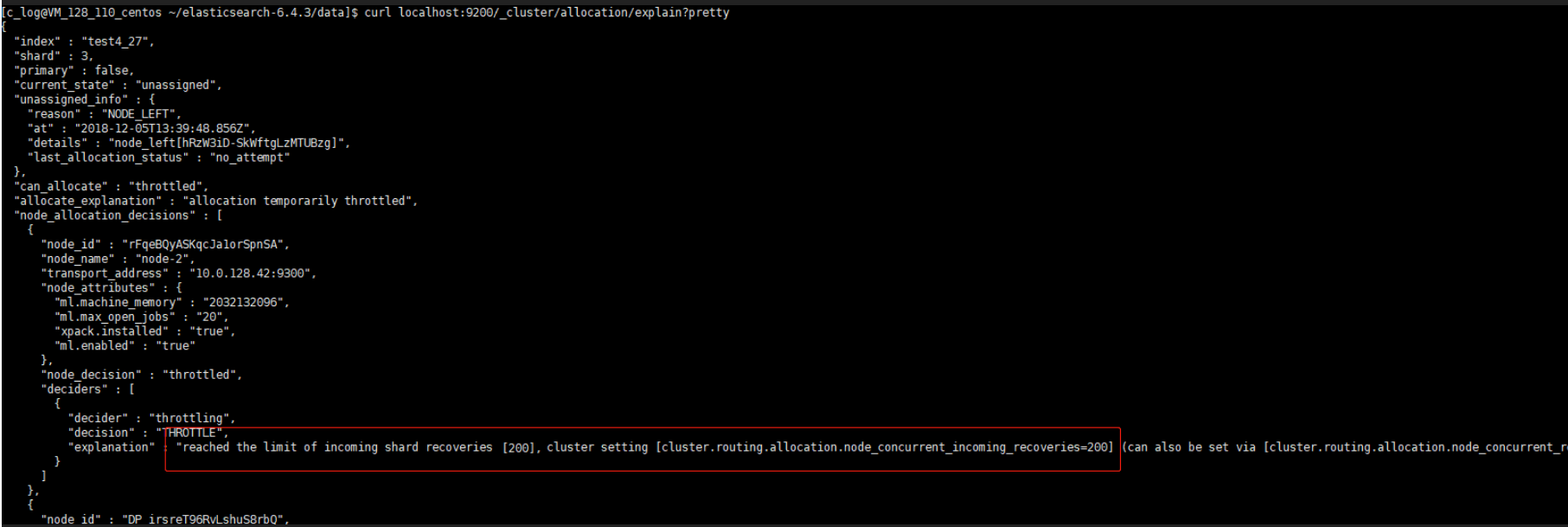
观察线程池的数量,generic 线程池打满128.

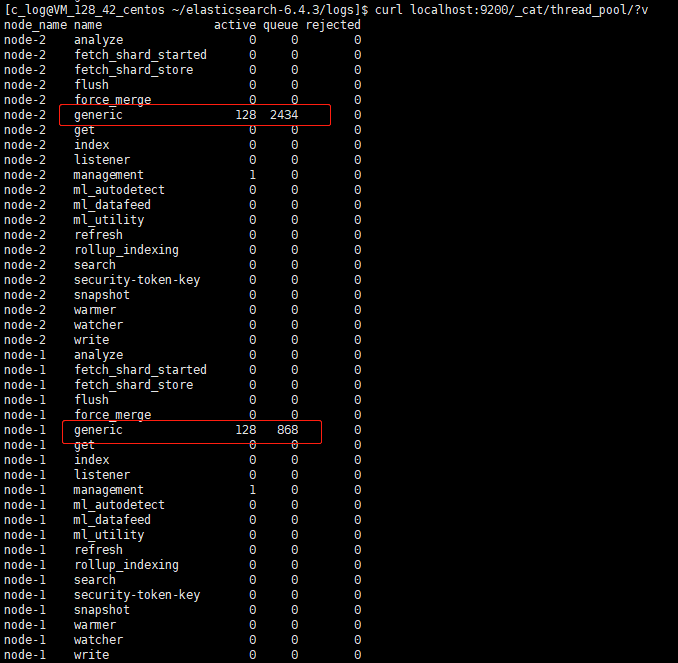
此时查询或写入已有索引不受影响,但是新建索引这种涉及到 generic 线程池的操作都会卡住。 通过堆栈分析,128 个 generic 线程全部卡在 PEER recovery 阶段。
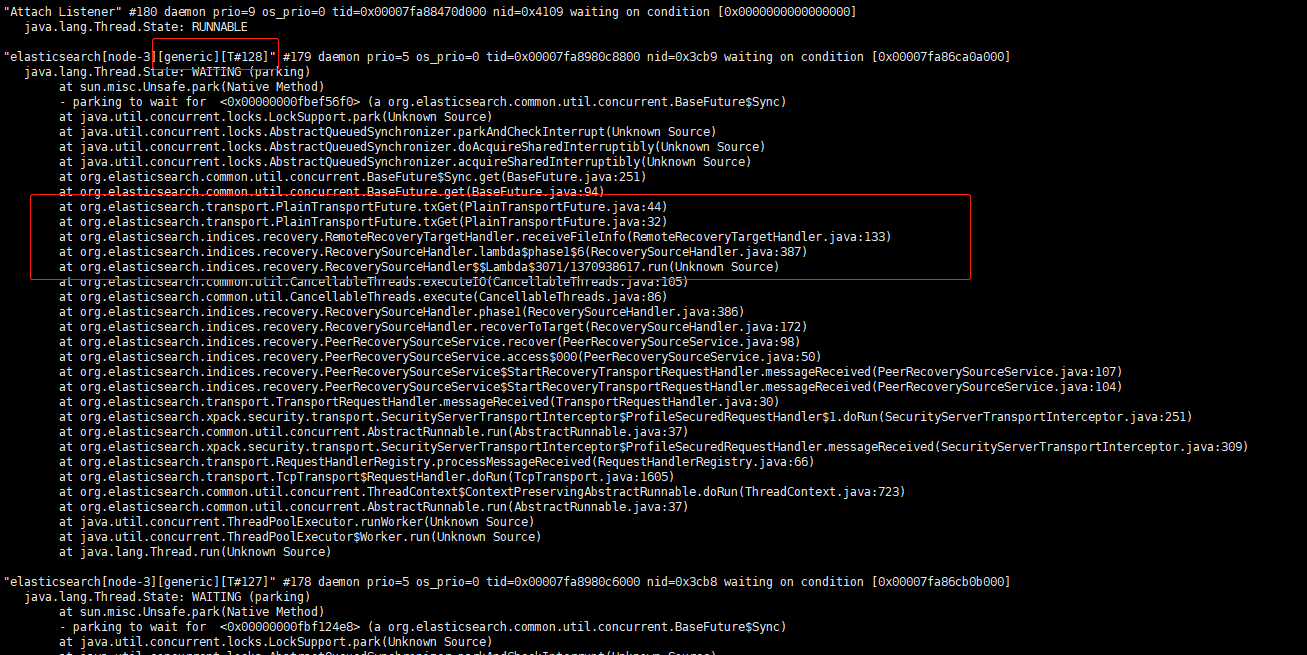
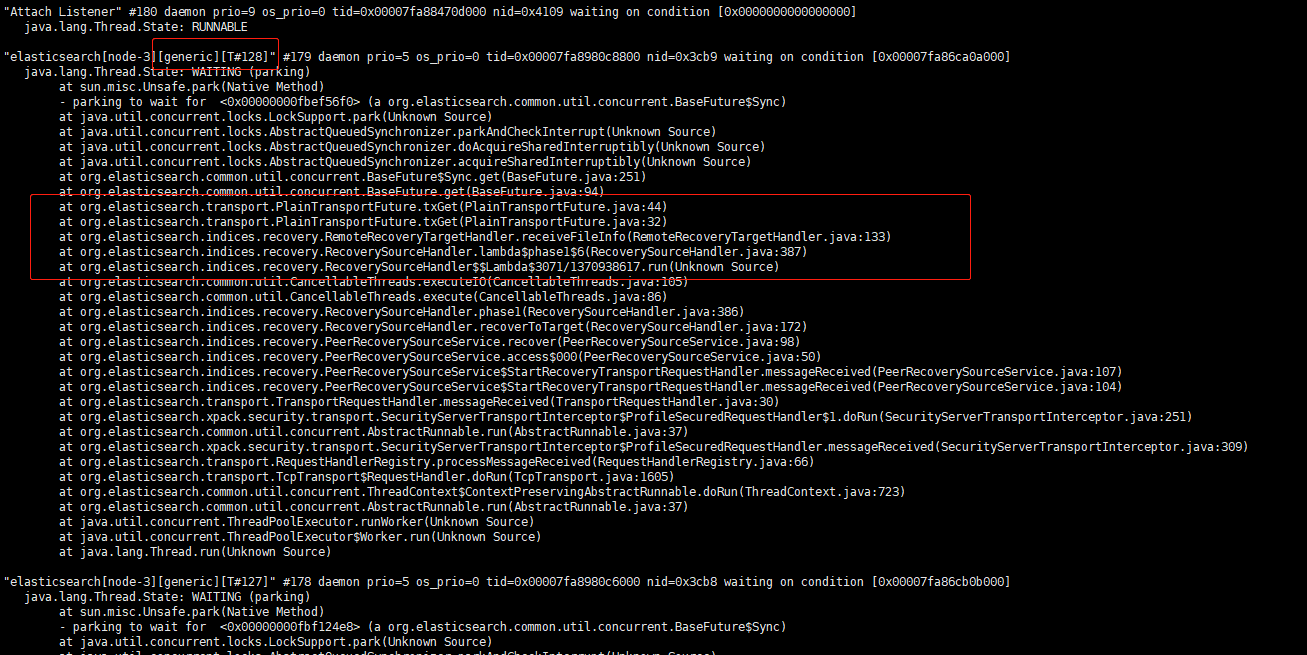
现象有了,我们来分析一下这种场景,远程分片恢复(PEER Recovery)流程为什么会导致集群卡住。
当集群中有分片的状态发生变更时,master 节点会发起集群元数据更新(cluster state update)请求给所有节点。其它节点收到该请求后,感知到分片状态的变更,启动分片恢复流程。部分分片需要从其它节点恢复,代码层面,涉及分片分配的目标节点(target)和源节点(source)的交互流程如下:
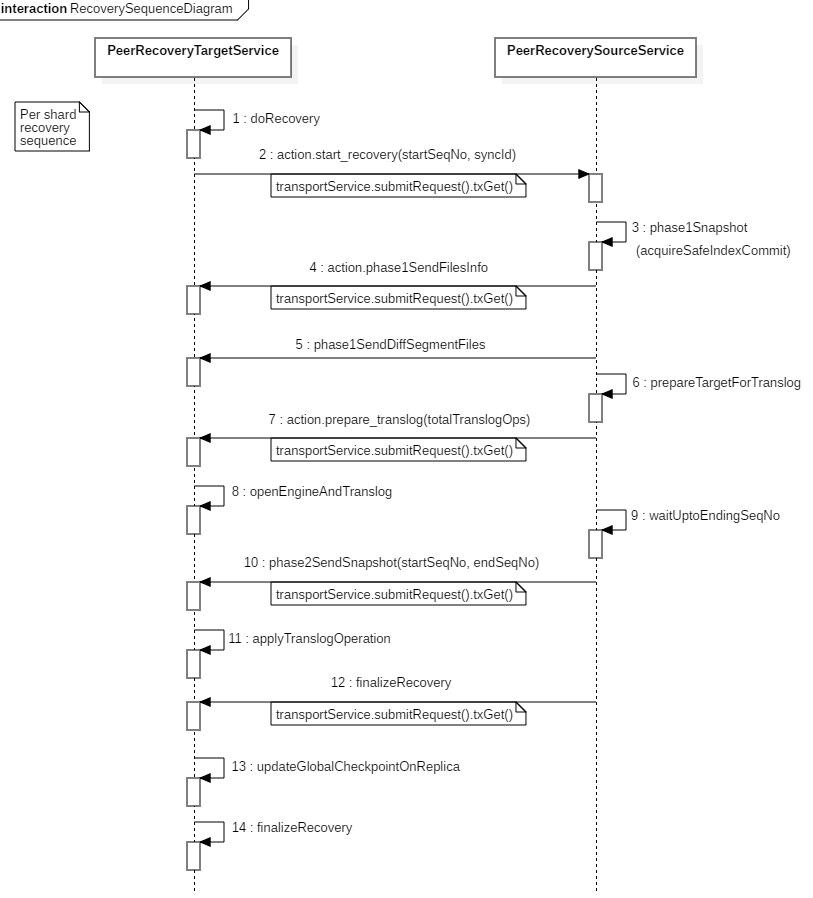
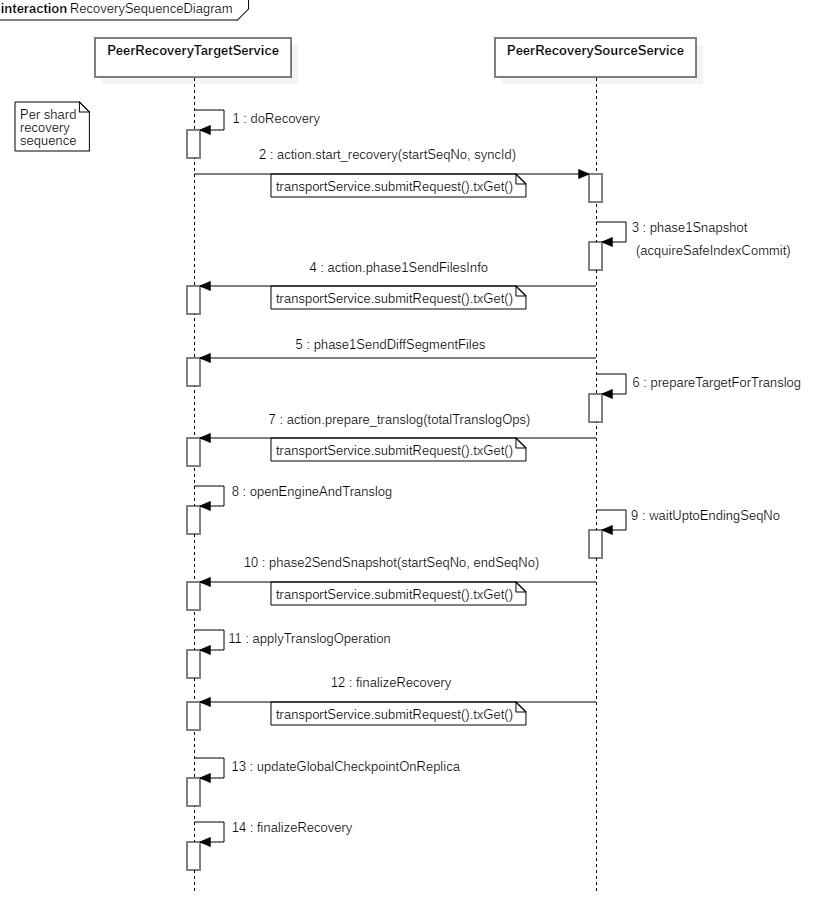
6.x 版本之后引入了 seqNo,恢复会涉及到 seqNo+translog,这也是6.x提升恢复速度的一大改进。我们重点关注流程中第 2、4、5、7、10、12 步骤中的远程调用,他们的作用分别是:
- 第2步:分片分配的目标节点向源节点(一般是主分片)发起分片恢复请求,携带起始 seqNo 和 syncId。
- 第4步:发送数据文件信息,告知目标节点待接收的文件清单。
- 第5步:发送 diff 数据文件给目标节点。
- 第7步:源节点发送 prepare translog 请求给目标节点,等目标节点打开 shard level 引擎,准备接受 translog。
- 第10步:源节点发送指定范围的 translog 快照给目标节点。
- 第12步:结束恢复流程。
我们可以看到除第5步发送数据文件外,多次远程交互 submitRequest 都会调用 txGet,这个调用底层用的是基于 AQS 改造过的 sync 对象,是一个同步调用。 如果一端 generic 线程池被这些请求打满,发出的请求等待对端返回,而发出的这些请求由于对端 generic 线程池同样的原因被打满,只能 pending 在队列中,这样两边的线程池都满了而且相互等待对端队列中的线程返回,就出现了分布式死锁现象。
Reference
- https://elasticsearch.cn/article/6184
- https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html
